Abstract:
Data measured and collected from embedded sensors often contains faults, i.e.,
data points which are not an accurate representation of the physical phenomenon
monitored by the sensor. These data faults may be caused by deployment conditions
outside the operational bounds for the node, and short- or long-term hardware,
software, or communication problems. On the other hand, the applications will
expect accurate sensor data, and recent literature proposes algorithmic solutions
for the fault detection and classification in sensor data.
In order to evaluate the performance of such solutions, however, the field lacks
a set of benchmark sensor datasets. A benchmark dataset ideally satisfies the
following criteria: (a) it is based on real-world raw sensor data from various
types of sensor deployments; (b) it contains (natural or artificially injected)
faulty data points reflecting various problems in the deployment, including
missing data points; and (c) all data points are annotated with the ground truth,
i.e., whether or not the data point is accurate, and, if faulty, the type of fault.
We prepare and publish three such benchmark datasets, together with the algorithmic
methods used to create them: a dataset of 280 temperature and light subsets of data
from 10 indoor Intel Lab sensors, a dataset of 140 subsets of outdoor temperature data
from SensorScope sensors, and a dataset of 224 subsets of outdoor temperature data from
16 Smart Santander sensors. The three benchmark datasets total 5.783.504 data points,
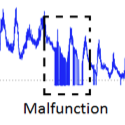
containing injected data faults of the following types known from the literature: random,
malfunction, bias, drift, polynomial drift, and combinations. We present algorithmic procedures
and a software tool for preparing further such benchmark datasets.